Convert Pandas Categorical Data For Scikit-Learn
Example 1: int Categorical Data
#import sklearn library
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# we are going to perform label encoding on this data
categorical_data = [1, 2, 2, 6]
# fitting data to model
le.fit(categorical_data)
#print no of classes or unique classes
print(le.classes_)
# [1 2 6]
# based on categorical_data class we are going to test this data class
print(le.transform([1, 1, 2, 6]))
#[0 0 1 2]
#getting back original data
print(le.inverse_transform([0, 0, 1, 2]))
#[1 1 2 6]
output:
[1 2 6] # class label
[0 0 1 2] # label after transform 1 --> 0, 2 --> 1, 6 --> 2
[1 1 2 6] # original data i. [1, 1, 2, 6]Example 2: string Categorical Data
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
categorical_data = ["india", "india", "tokyo", "paris"]
#fitting
le.fit(categorical_data)
print(list(le.classes_)) # ['india', 'paris', 'tokyo']
print(le.transform(["tokyo", "tokyo", "paris"])) # [2 2 1]
#getting back original category
print(list(le.inverse_transform([2, 2, 1]))) # ['tokyo', 'tokyo', 'paris']Output:
['india', 'paris', 'tokyo'] [2 2 1] ['tokyo', 'tokyo', 'paris']
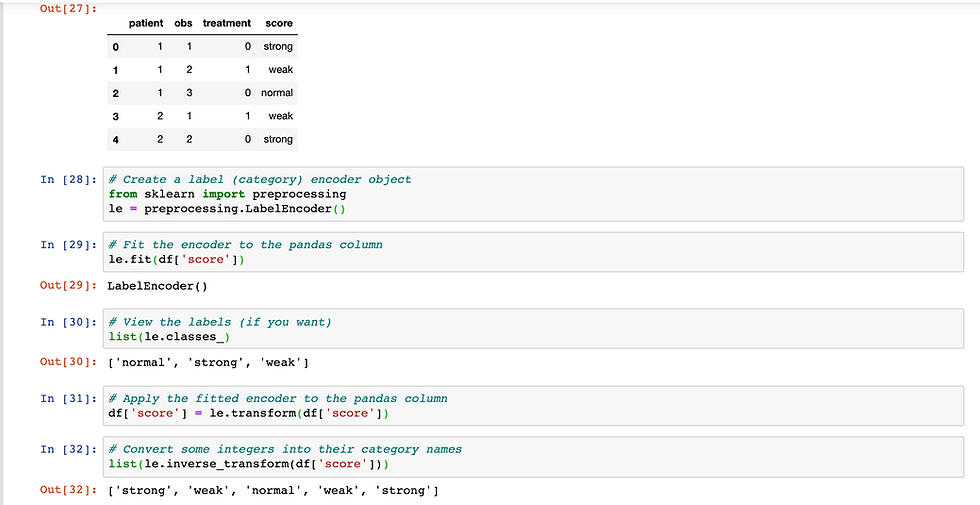
Example 3: label encoding on pandas dataframe
Create DataFrame
raw_data = {'patient': [1, 1, 1, 2, 2],
'obs': [1, 2, 3, 1, 2],
'treatment': [0, 1, 0, 1, 0],
'score': ['strong', 'weak', 'normal', 'weak', 'strong']}
df = pd.DataFrame(raw_data, columns = ['patient', 'obs', 'treatment', 'score'])
Fit The Label Encoder
# Create a label (category) encoder object
le = preprocessing.LabelEncoder()# Fit the encoder to the pandas column
le.fit(df['score'])View The Labels
# View the labels (if you want)
list(le.classes_)Transform Categories Into Integers
# Apply the fitted encoder to the pandas column
df['score'] = le.transform(df['score'])
Transform Integers Into Categories
# Convert some integers into their category names
list(le.inverse_transform(df['score']))output:
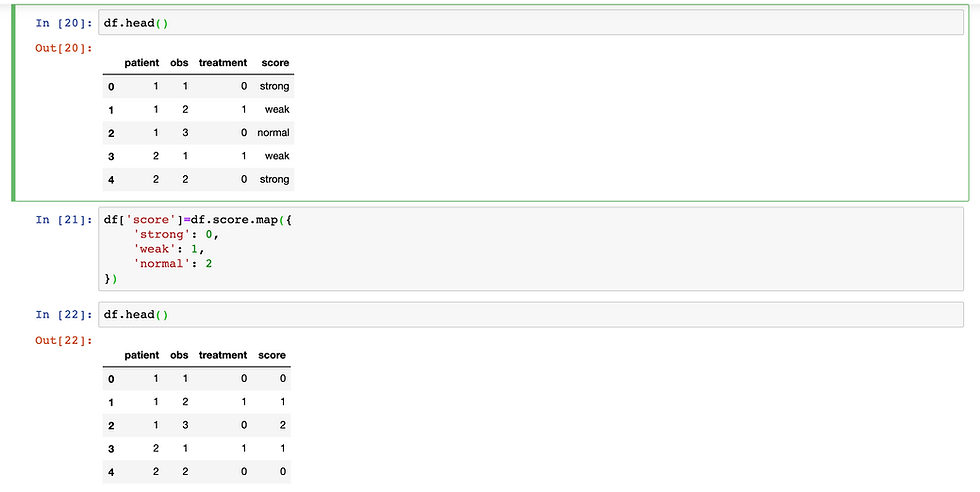
Example 4: label encoding with map
Create dataframe
import pandas as pd
raw_data = {'patient': [1, 1, 1, 2, 2],
'obs': [1, 2, 3, 1, 2],
'treatment': [0, 1, 0, 1, 0],
'score': ['strong', 'weak', 'normal', 'weak', 'strong']}
df = pd.DataFrame(raw_data, columns = ['patient', 'obs', 'treatment', 'score'])
Apply mapping
df['score']=df.score.map({
'strong': 0,
'weak': 1,
'normal': 2
})Output: