Learn how to analyze data using Python. This blog will take you from the basics of Python to exploring many different types of data. You will learn how to prepare data for analysis, perform simple statistical analyses, create meaningful data visualizations, predict future trends from data, and more!
1- You will learn how to:
2- Import data sets
3- Clean and prepare data for analysis
4- Manipulate pandas DataFrame
5- Summarize data
Python itself does not include vectors, matrices, or dataframes as fundamental data types. As Python became an increasingly popular language, however, it was quickly realized that this was a major short-coming, and new libraries were created that added these data-types (and did so in a very, very high performance manner) to Python.
The original library that added vectors and matrices to Python was called numpy. But numpy, while very powerful, was a no-frills library. You couldn’t do things like mix data-types, label your columns, etc.. To remedy this shortcoming a new library was created – built on top of numpy – that added all the nice features we’ve come to expect from modern languages: pandas.
Creating A DataFrame in Pandas:
Method 1:
import pandas as pd
dframe = pd.DataFrame({
"c1": [1, "Ashish"],
"c2": [2, "Sid"]})
print(dframe)
Output:

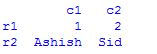
Method 2:
# taking index and column values
import pandas as pd
dframe = pd.DataFrame([[1,2],["Ashish", "Sid"]],
index=["r1", "r2"],
columns=["c1", "c2"])
print(dframe)
Output:
Importing Data with Pandas:
import pandas as pd
df=pd.read_csv(" csvfile.csv")
# Prints the first 5 rows of a DataFrame as default
df.head()
# Prints no. of rows and columns of a DataFrame
df.shape
Kommentarer