AWS Serverless Machine Learning Pipeline for Sentiment Analysis
- Aug 16, 2024
- 5 min read
In today's fast-paced digital landscape, businesses increasingly rely on data-driven insights to make informed decisions. Sentiment analysis, a critical component of natural language processing (NLP), enables organizations to gauge public opinion, customer satisfaction, and market trends by analyzing textual data from social media, reviews, and other sources. Building a machine learning pipeline for sentiment analysis can be a complex task, but with AWS's serverless offerings, it becomes more accessible and scalable.
In this blog, we'll explore how to create a serverless machine learning pipeline on AWS for sentiment analysis.
Why Go Serverless?
Serverless architecture offers several advantages, particularly for machine learning applications:
Scalability: Automatically scales with the volume of data without manual intervention.
Cost Efficiency: Pay only for what you use, eliminating the need for provisioning and maintaining servers.
Ease of Deployment: Simplifies deployment processes, allowing data scientists and developers to focus on model development and data processing.
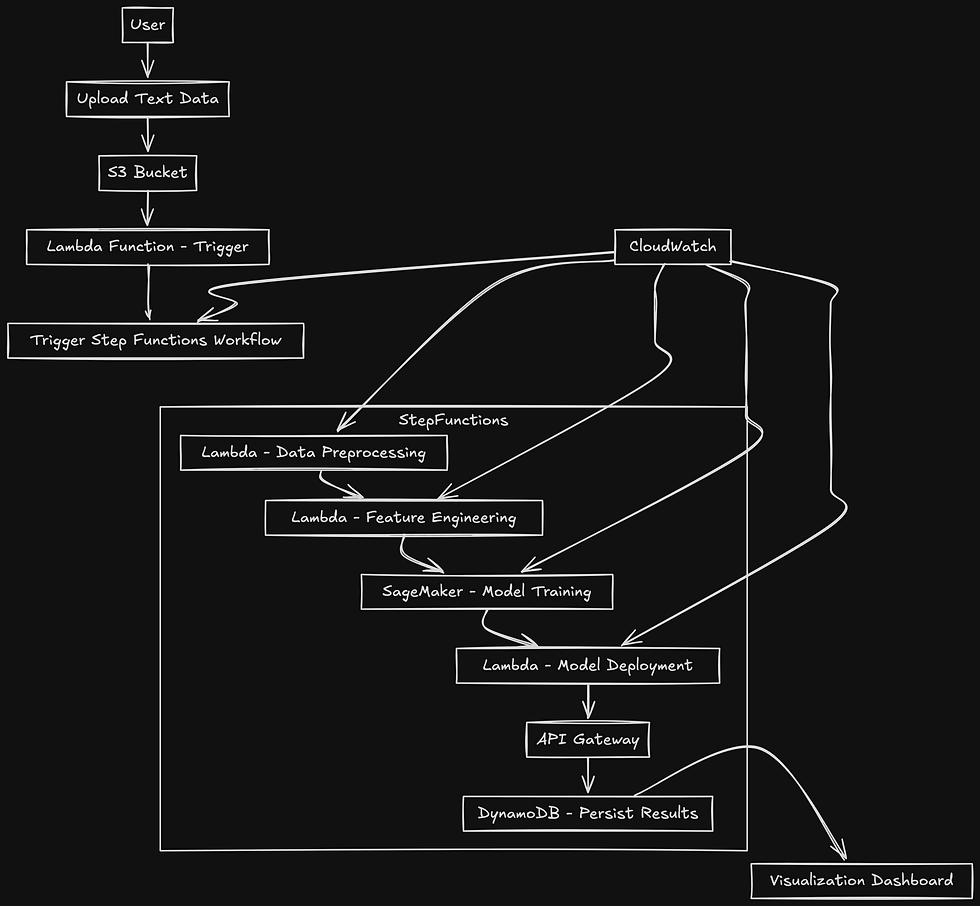
Pipeline Overview
Our serverless sentiment analysis pipeline will consist of the following components:
Data Ingestion: Capturing raw data from sources like social media or customer reviews.
Data Preprocessing: Cleaning and transforming data into a format suitable for sentiment analysis.
Model Inference: Using a pre-trained machine learning model to analyze sentiment.
Results Storage: Storing the sentiment results for further analysis or visualization.
Monitoring and Logging: Keeping track of the pipeline's performance and ensuring smooth operation.
AWS provides several services to build this pipeline:
Amazon S3: For storing raw data and results.
AWS Lambda: For executing the preprocessing and inference steps.
Amazon SageMaker: For deploying pre-trained models.
Amazon DynamoDB or Amazon RDS: For storing processed results.
Amazon CloudWatch: For monitoring and logging.
Step-by-Step Implementation
Step 1: Data Ingestion with Amazon S3
The first step in our pipeline is to gather raw textual data. We'll use Amazon S3 to store this data. You can upload text files directly to an S3 bucket or automate data ingestion from sources like social media using services like AWS Glue or third-party APIs.
aws s3 cp your-data.txt s3://your-bucket-name/raw-data/
Step 2: Data Preprocessing with AWS Lambda
Once the data is in S3, we need to preprocess it before feeding it into our sentiment analysis model. AWS Lambda is ideal for this task due to its event-driven nature. When a new file is uploaded to the S3 bucket, a Lambda function can be triggered to clean and tokenize the text data.
Here’s a simple Python script for a Lambda function that performs basic text preprocessing:
import json
import boto3
from nltk.tokenize import word_tokenize
def lambda_handler(event, context):
s3 = boto3.client('s3')
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Get the file from S3
response = s3.get_object(Bucket=bucket, Key=key)
text = response['Body'].read().decode('utf-8')
# Basic preprocessing: tokenization
tokens = word_tokenize(text)
# Save processed data back to S3
processed_key = key.replace('raw-data', 'processed-data')
s3.put_object(Bucket=bucket, Key=processed_key, Body=json.dumps(tokens))
return {
'statusCode': 200,
'body': json.dumps('Data preprocessing complete!')
}
Step 3: Model Inference with Amazon SageMaker and AWS Lambda
For sentiment analysis, you can either train a model from scratch using Amazon SageMaker or use a pre-trained model. SageMaker offers built-in algorithms and pre-trained models that can be deployed quickly.
In this example, we'll use a pre-trained model hosted on SageMaker. The Lambda function, triggered by the completion of preprocessing, sends the processed data to SageMaker for inference.
import boto3
def lambda_handler(event, context):
sagemaker = boto3.client('sagemaker-runtime')
# Prepare input for SageMaker
processed_data = event['processed_data']
response = sagemaker.invoke_endpoint(
EndpointName='your-endpoint-name',
ContentType='application/json',
Body=processed_data
)
result = json.loads(response['Body'].read())
return {
'statusCode': 200,
'body': json.dumps(result)
}
Step 4: Storing Results with DynamoDB or Amazon RDS
After obtaining the sentiment analysis results, store them in a database for future reference or further analysis. Amazon DynamoDB is a great choice for this due to its flexibility and scalability.
import boto3
def lambda_handler(event, context):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('SentimentAnalysisResults')
result = event['sentiment_result']
table.put_item(Item={
'id': 'some-unique-id',
'text': event['original_text'],
'sentiment': result['sentiment'],
'confidence': result['confidence']
})
return {
'statusCode': 200,
'body': json.dumps('Result stored in DynamoDB!')
}
Step 5: Monitoring and Logging with CloudWatch
AWS CloudWatch is essential for monitoring the performance of your pipeline and logging errors. Configure CloudWatch to capture logs from Lambda functions and set up alarms to notify you of any issues in the pipeline.
Conclusion
By leveraging AWS's serverless offerings, you can create a scalable, cost-effective, and easy-to-maintain machine learning pipeline for sentiment analysis. This approach allows you to focus on refining your model and analyzing results without worrying about infrastructure management. Whether you're processing thousands of customer reviews or analyzing social media sentiment, this pipeline can handle the workload seamlessly.
Building such a pipeline with AWS also ensures that you can easily integrate other AWS services, like Amazon Comprehend for more advanced NLP tasks, or AWS Glue for more complex data processing workflows. The flexibility of AWS's serverless architecture makes it an excellent choice for machine learning applications in a rapidly changing digital environment.
Elevate Your Machine Learning Projects with Codersarts
Are you ready to transform your business with cutting-edge machine learning solutions on AWS? At Codersarts, we specialize in end-to-end implementation of serverless machine learning pipelines, just like the one described above. Whether you need support for project setup, training, consulting, or even job support, our expert team is here to guide you every step of the way.
Unlock the full potential of your data with our expertise in:
Amazon S3: Securely store and manage raw data and results.
AWS Lambda: Seamlessly execute preprocessing and inference steps with event-driven architecture.
Amazon SageMaker: Deploy and manage pre-trained machine learning models with ease.
Amazon DynamoDB or Amazon RDS: Efficiently store and query processed results.
Amazon CloudWatch: Monitor and log your pipeline’s performance to ensure smooth operations.
We provide tailored services to meet your needs:
Expert Support: Get hands-on assistance from our experienced professionals.
End-to-End Implementation: From data ingestion to model deployment, we handle it all.
Training & Consulting: Empower your team with the skills and knowledge they need.
Job Support: Overcome challenges in your current role with our specialized help.
Don’t let technical hurdles slow you down—partner with Codersarts and accelerate your journey to success!
Get in touch with us today to discuss how we can help you achieve your goals.
Looking for AWS Machine Learning Experts? Hire Freelancers, Developers, and Mentors Today!
Keywords: AWS Machine Learning Freelancer, AWS Lambda Developer, Amazon SageMaker Expert, Serverless Pipeline Consultant, Amazon S3 Storage Specialist, DynamoDB Freelance Developer, RDS Database Consultant, CloudWatch Monitoring Expert, Machine Learning Mentor AWS, AWS Data Pipeline Developer, Serverless Machine Learning Consultant, Sentiment Analysis Expert AWS, AWS Machine Learning Implementation Support, Freelance Machine Learning Engineer, SageMaker Model Deployment Mentor, Lambda Function Development Support, Amazon Web Services Data Engineer, AWS Cloud Solutions Architect, Mentorship in AWS Machine Learning, Serverless Architecture Consultant AWS



Comments