
Description :
The dataset consists of various customers of a bank with their credit limit, the total number of credit cards the customer has, and different channels through which customer has contacted the bank for any queries, different channels include visiting the bank, online or through a call center.
Recommended Model :
Algorithms to be used: KMeans, KNN, Agglomerative clustering etc.
Recommended Project :
Customer Segmentation.
Dataset link:
Overview of data
Detailed overview of dataset:
- Rows = 660
- Columns= 7
Columns description:
Sl_No Customer Key - Customer Key is unique number for each customer
Avg_Credit_Limit - average credit limit for each customer
Total_Credit_Cards - total number of credit cards each customer owns
Total_visits_bank - total number of times customer visit bank
Total_visits_online - total number of times customer visit online banking
Total_calls_made - total number of times customer make calls to bank
EDA [CODE]
import pandas as pd
# load data data = pd.read_csv('telecom.csv')
data.head()
# check details of the dataframe
data.info()
# check the no.of missing values in each column
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'], errors = 'coerce') # change TotalCharges to numeric dtype
data.isna().sum()
# statistical information about the dataset
data.describe()
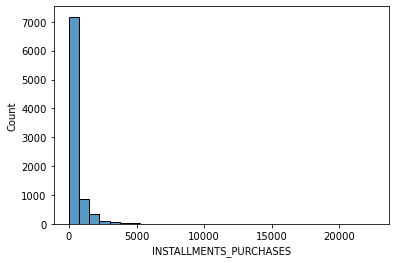
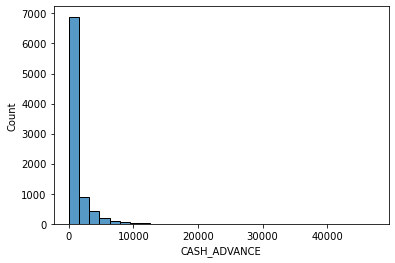
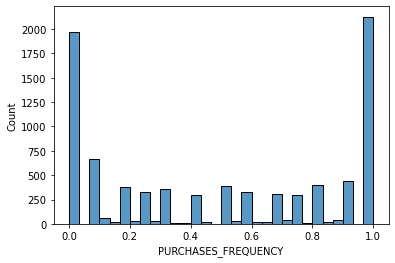
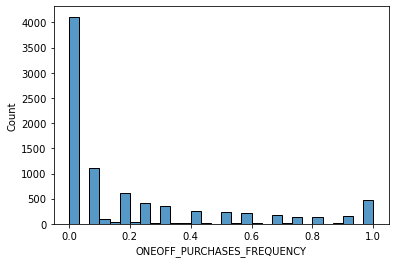
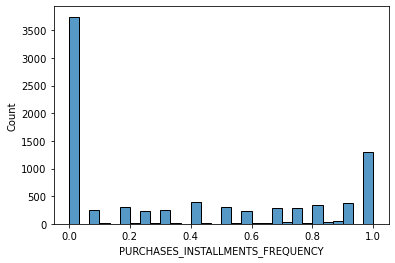
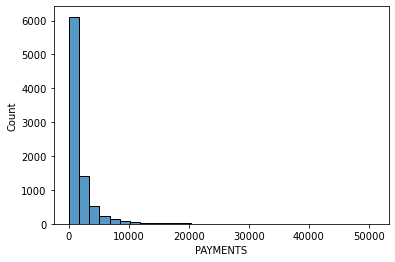
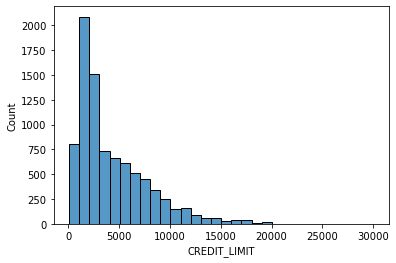
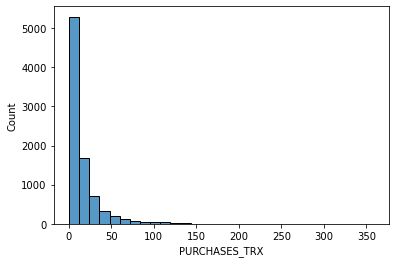
# data distribution
import seaborn as sns
import matplotlib.pyplot as plt
data = data.dropna() # removing missing value
for i in data.columns[1:]:
sns.histplot(data[i], bins=30,kde=False)
plt.show()
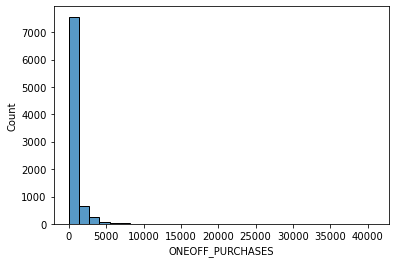

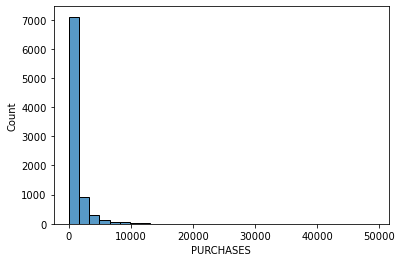

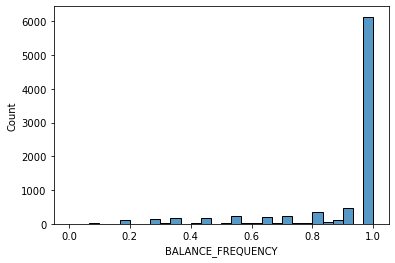

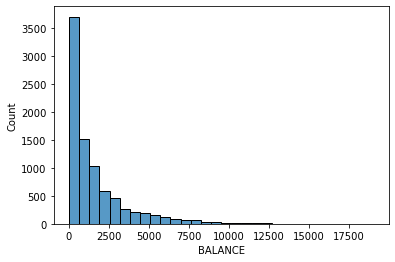









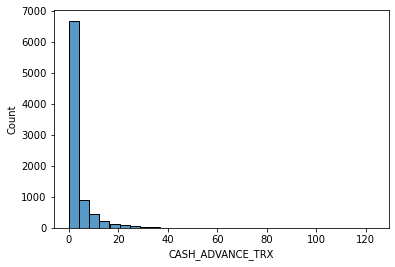

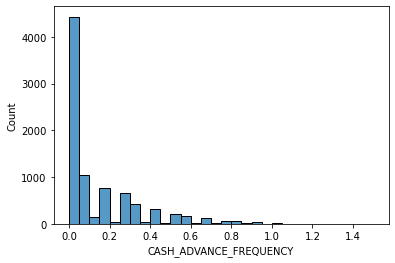

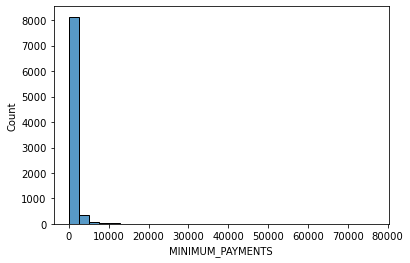

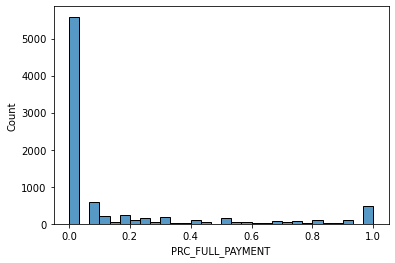

Other datasets for classification:
If you need implementation for any of the topics mentioned above or assignment help on any of its variants, feel free to contact us

Comments