
In this project, we aim to apply different classification techniques to solve the problem of predicting Hotel Booking Cancellations.
Context
A significant number of hotel bookings are called off due to cancellations or no-shows. The typical reasons for cancellations include change of plans, scheduling conflicts, etc. This is often made easier by the option to do so free of charge or preferably at a low cost which is beneficial to hotel guests but it is a less desirable and possibly revenue-diminishing factor for hotels to deal with. Such losses are particularly high on last-minute cancellations.
The new technologies involving online booking channels have dramatically changed customers’ booking possibilities and behavior. This adds a further dimension to the challenge of how hotels handle cancellations, which are no longer limited to traditional booking and guest characteristics.
The cancellation of bookings impacts a hotel on various fronts: 1. Loss of resources (revenue) when the hotel cannot resell the room. 2. Additional costs of distribution channels by increasing commissions or paying for publicity to help sell these rooms. 3. Lowering prices last minute, so the hotel can resell a room, reducing the profit margin. 4. Human resources to make arrangements for the guests.
Objective
The increasing number of cancellations calls for a Machine Learning based solution that can help predict which booking is likely to be canceled. INN Hotels Group has a chain of hotels in Portugal, they are facing problems with the high number of booking cancellations and have reached out to your firm for data-driven solutions. You as a data scientist have to analyze the data provided to find which factors have a high influence on booking cancellations, build a predictive model that can predict which booking is going to be canceled in advance, and help in formulating profitable policies for cancellations and refunds.
Data Description
The data contains the different attributes of customers' booking details. The detailed data dictionary is given below.
Data Dictionary
Booking_ID: the unique identifier of each booking
no_of_adults: Number of adults
no_of_children: Number of Children
no_of_weekend_nights: Number of weekend nights (Saturday or Sunday) the guest stayed or booked to stay at the hotel
no_of_week_nights: Number of weeknights (Monday to Friday) the guest stayed or booked to stay at the hotel
type_of_meal_plan: Type of meal plan booked by the customer:
Not Selected – No meal plan selected
Meal Plan 1 – Breakfast
Meal Plan 2 – Half board (breakfast and one other meal)
Meal Plan 3 – Full board (breakfast, lunch, and dinner)
required_car_parking_space: Does the customer require a car parking space? (0 - No, 1- Yes)
room_type_reserved: Type of room reserved by the customer. The values are ciphered (encoded) by INN Hotels Group
lead_time: Number of days between the date of booking and the arrival date
arrival_year: Year of arrival date
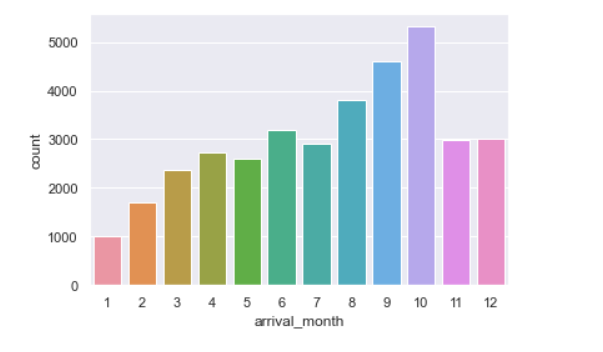
arrival_month: Month of arrival date
arrival_date: Date of the month
market_segment_type: Market segment designation.
repeated_guest: Is the customer a repeated guest? (0 - No, 1- Yes)
no_of_previous_cancellations: Number of previous bookings that were canceled by the customer prior to the current booking
no_of_previous_bookings_not_canceled: Number of previous bookings not canceled by the customer prior to the current booking
avg_price_per_room: Average price per day of the reservation; prices of the rooms are dynamic. (in euros)
no_of_special_requests: Total number of special requests made by the customer (e.g. high floor, view from the room, etc)
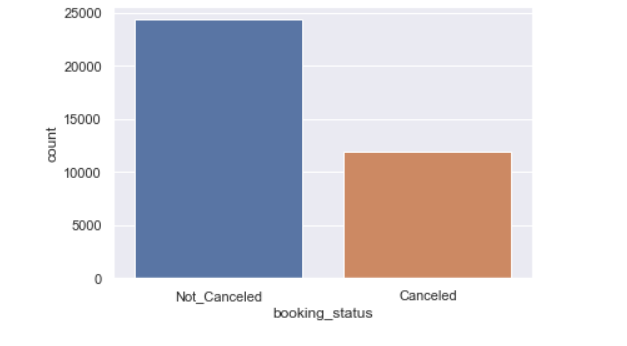
booking_status: Flag indicating if the booking was canceled or not.
Key Points to Note:
Please do not change the variable names to avoid hassles while executing the code.
The notebook should be run from start to finish in a sequential manner before submission. It is preferable to remove all warnings and errors before submission.
You need to submit a Python notebook in HTML format.
The naming convention for the notebook will be FirstnameLastname_CHT.html.
Question 1: Check the summary statistics of the dataset and write your observations
Question 2: Univariate Analysis
Question 2.1: Plot the histogram and box plot for the variable Lead Time using the hist_box function provided and write your insights.
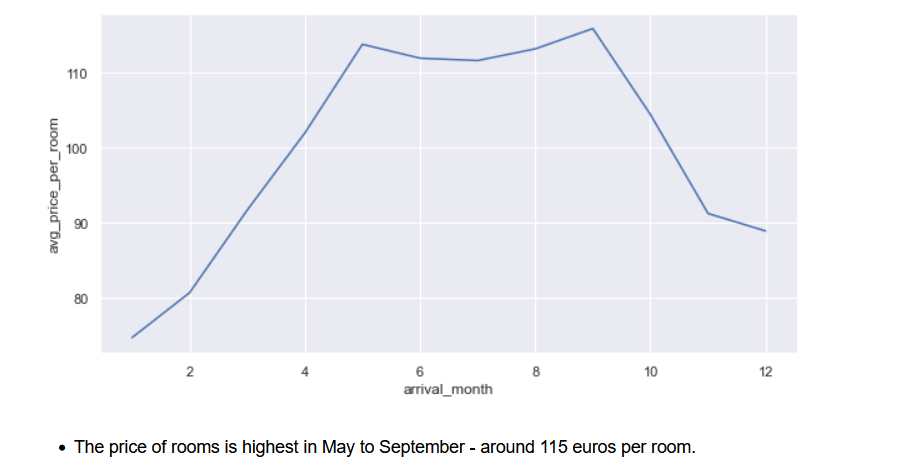
Question 2.2: Plot the histogram and box plot for the variable Average Price per Room using the hist_box function provided and write your insights.
Question 3: Bivariate Analysis
Question 3.1: Find and visualize the correlation matrix using a heatmap and write your observations from the plot.
Question 3.2: Plot the stacked barplot for the variable Market Segment Type against the target variable Booking Status using the stacked_barplot function provided and write your insights.
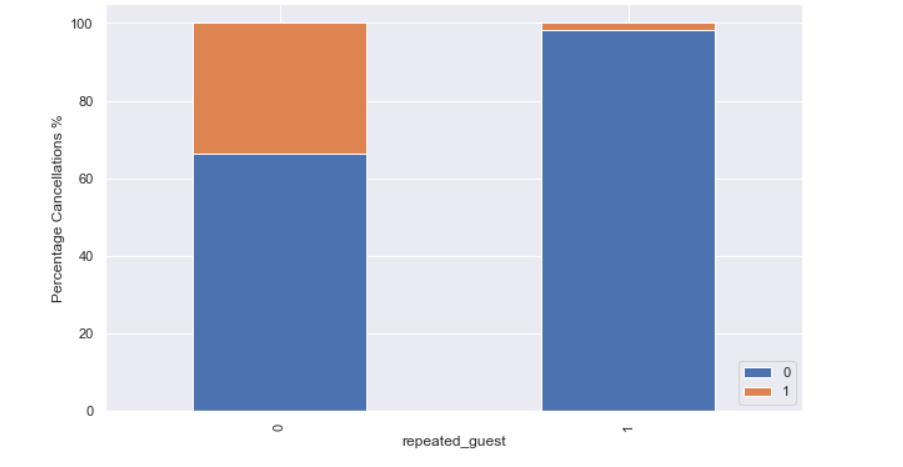
Question 3.3: Plot the stacked barplot for the variable Repeated Guest against the target variable Booking Status using the stacked_barplot function provided and write your insights.
Question 4: Logistic Regression
Question 4.1: Build a Logistic Regression model (Use the sklearn library) Question 4.2: Check the performance of the model on train and test data
Question 4.3: Find the optimal threshold for the model using the Precision-Recall Curve.
Question 4.4: Check the performance of the model on train and test data using the optimal threshold.
Question 5: Support Vector Machines
Question 5.1: Build a Support Vector Machine model using a linear kernel-Comment on model performance
Question 5.2: Check the performance of the model on train and test data
Question 5.3: Find the optimal threshold for the model using the Precision-Recall Curve.
Question 5.4: Check the performance of the model on train and test data using the optimal threshold.
Question 5.5: Build a Support Vector Machines model using RBF kernel
Question 5.6: Check the performance of the model on train and test data
Question 5.7: Check the performance of the model on train and test data using the optimal threshold.
Question 6: Decision Trees
Question 6.1: Build a Decision Tree Model
Question 6.2: Check the performance of the model on train and test data
Question 6.3: Perform hyperparameter tuning for the decision tree model using GridSearchCV
Question 6.4: Check the performance of the model on the train and test data using the tuned model
Question 6.5: What are some important features based on the tuned decision tree?
Question 7: Random Forest
Question 7.1: Build a Random Forest Model
Question 7.2: Check the performance of the model on the train and test data
Question 7.3: What are some important features based on the Random Forest?
Question 8: Conclude ANY FOUR key takeaways for business recommendations
Sample solution:





































This project can be used as final year project, capstone project, personal portfolio project, resume, proof of concept.
If you need implementation for the above problem or any of its variants, feel free to contact us.

Comments