
When you have such a large data set that you can’t understand the relationship between the variables or there is a risk of overfitting your model to the data or you can’t decide which features to remove and on which features to focus on and if you are okay with making your independent variables less understandable, then Principal Component Analysis (PCA) comes to your rescue.
Principal Component Analysis is a very useful statistical technique that has found application in fields such as face recognition and image compression, and is a common technique for finding patterns in data of high dimension. It is a method that is often used to reduce the dimensionality of large data sets, by transforming a larger set of variables into a smaller one that still maps most of the relationships in the larger set.
Before going too deep into the workings of PCA, we will discuss a few mathematical concepts that are used in it. We will cover standard deviation, covariance, eigenvectors and eigenvalues. This background knowledge is meant to help understand PCA easily, but can be skipped if the concepts are already familiar.
Mathematical Concepts:
Standard Deviation (SD):It is a measure of how spread out is a data set. It is the average distance from the mean of the data set to a point. To calculate it we compute the squares of the distance from each data point to the mean of the set, then add them all up and divide by n-1 ( n is the no. of points in the data set) , and take the positive square root. The mathematical representation of SD is:

Variance: It is another measure of the spread of data in a data set. It is the square of Standard Deviation. The mathematical representation of variance is.
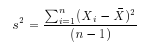
Covariance: The measures we discussed above are useful when dealing with 1-dimensional data set only. If we have an n-dimensional data set, we can only calculate SD and variance for each dimension of the data set independent of other dimensions. If we want to find out how much dimensions vary from the mean, with respect to each other, we calculate the covariance.
It is always measured for two dimensions i.e. if you have a 3-dimensional data set (x, y, z), then you can measure the covariance between x and y dimensions, y and z dimensions, and x and z dimensions. Measuring the covariance between x and x, or y and y, or z and z, would give you the variance of x, y and z dimensions respectively. The mathematical representation of covariance is:

The exact value of covariance is not as important as its sign (i.e. positive or negative). If it is positive, then that indicates that two dimensions increase together, if it is negative, then as one dimension increases, the other decreases. If the covariance is zero, it indicates that the two dimensions are independent of each other.
Covariance Matrix: For n-dimensional data set, we can calculate n!/((n-2)! x 2) different covariance values. It would be convenient to calculate all the possible covariance values between all the dimensions and put them in a matrix. The matrix is called Covariance matrix. The mathematical representation for the covariance matrix of a set of data with n- dimensions is:

where C(nxn) is a matrix with n rows and n columns, Dim(x) is the x-th dimension. All this complex looking formula says is that, if you have an n-dimensional data set, then the matrix has n rows and columns (so is square) and each entry in the matrix is the result of calculating the covariance between two separate dimensions.

Eigen values and Eigen vectors: These two concepts lie at the heart of PCA. When we have a large data set in the form of a matrix, It becomes a hassle to manage it and it also consumes a lot of space on a disk. Therefore, we aim towards compressing the data in such a way that it holds on to the important information. For such purposes, we can use Eigenvectors and Eigenvalues to reduce the dimensions.
In simple words, all of the information which doesn’t impact the data set in a crucial manner is reduced so that only the key information is retained.
We know that a vector contains the magnitude and direction of a particular movement. Also, when we multiply a matrix (i.e., transformation matrix). with a vector, we get a new vector. This new transformed vector is often times the scaled version of the original vector and other times it has no scalar relationship with the original vector.
Here, the first type of vector is important. This vector is called the eigenvector. These vectors are used to represent the large dimensional matrices. These vectors are also called special vectors, because it does not change when a transformation is applied to it. It only becomes a scaled version of the original vector.
Hence, the large matrix T can be replaced by a vector v, given that the product of matrix T and vector v is the same as the product of vector v and scalar b.
T*v=b*v
Here, b is the Eigen value and v is the Eigen vector.
In this way, eigenvectors help us in calculating the approximation of a large matrix as a smaller vector. And eigenvalues are the scalar quantity that is used to transform (or stretch) an eigenvector.
Now that we are familiar with the mathematical concepts we can move ahead with the working of PCA.
Steps to perform PCA:
Step 1: Get some data.
Step 2: Subtract the mean:
For PCA to work properly, for each column of a matrix you need to subtract the mean of that column from each entry. So, all the x values have x̅ (the mean of the x values of all the data points) subtracted, and all the y values have y̅ subtracted from them. This produces a mean centered data set whose mean is zero.
Step 3: Calculate the covariance matrix.
Step 4: Calculate the eigenvectors and eigenvalues of the covariance matrix.
Step 5: Choose components and form a feature vector:
Here is where the notion of data compression and reduced dimensionality comes into it. It turns out that the eigenvector with the highest eigenvalue is the principle component of the data set. It is the most significant relationship between the features of the data set. In general, once eigenvectors are found from the covariance matrix, the next step is to order them by eigenvalue, highest to lowest. This gives you the components in order of significance.
Now, if you like, you can decide to ignore the components of lesser significance. You do lose some information, but if the eigenvalues are small, you don’t lose much. If you leave out some components, the final data set will have less dimensions than the original.
To be precise, if you originally have n dimensions in your data, and so you calculate n eigenvectors and eigenvalues, and then you choose only the first p eigenvectors, then the final data set has only p dimensions.
What needs to be done next is that you need to form a feature vector. This is constructed by taking the eigenvectors that you want to keep from the list of sorted eigenvectors (high to low), and forming a matrix with these eigenvectors in the columns.
Step 6: Derive the new data set:
Once we have chosen the components (eigenvectors) that we wish to keep in our data and formed a feature vector, we simply take the transpose of the vector and multiply it with the transposed mean centered data set.
Final Data= ( Feature vector_T ) x ( Original centered data set_T )
where _T represents transpose, ( Feature vector_T ) represents the eigenvectors in rows instead of columns and ( Original centered data set_T ) {from step 2} represents data items in each column, with each row holding a separate dimension. Final data is the final data set, with data items in columns, and dimensions along rows.
It will give us the original data solely in terms of the vectors we chose
.
**The original data is then reoriented from the original axes to the ones represented by the principal components (hence the name Principal Components Analysis).**
It should be noted that if we had taken all the eigenvectors in the feature vector then we will get the exact original data back.
STEP 7: Get the old data back (reconstruction):
If we reverse the equation given in step 6 we can get the original data back i.e.
Original centered data set = ( Feature vector_T )^(-1) x Final Data
the inverse of our feature vector is actually equal to the transpose of our feature vector. Thus,
Original centered data set = ( Feature vector_T )_T x Final Data
The above equation gives back the centered original data set but to get the exact original data back, you need to add on the mean of that original data (remember we subtracted it in step 2). So, for completeness,
Original centered data set = { ( Feature vector_T )_T x Final Data } + Mean
Example:
Let us consider an example of reconstruction of a grayscale image which utilizes eigen decomposition technique for dimensionality reduction as discussed above. We will look at results corresponding to feature vector consisting of various top p-eigen vectors to get an idea of the functionality of PCA for dimension reduction.
Original grayscale image:

Reconstruction with top 10 eigen vectors

Reconstruction with top 30 eigen vectors

Reconstruction with top 50 eigen vectors

Reconstruction with top 100 eigen vectors

Reconstruction with top 500 eigen vectors

In the above example we can see that even top 100 eigenvectors were insufficient to represent the original data while top 500 eigenvectors were able to represent the data more closely than other values but with some loss of information. The value of eigenvectors that can sufficiently represent the original data varies from one problem to another.
Don't get intimidated by the complexity of the mathematical concepts. There are various packages available (for example Scikit learn) to do the mathematical calculations for you. The import thing is to get the idea of what all these methods are doing to the data which can be achieved by trying your hands on various problems.
Comments